Lite Browser QA Skill
A lightweight, tiered approach to browser-based visual QA — from quick screenshots to full interaction testing, without the flakiness of traditional browser automation.
What problem does this solve?
Every time a developer changes CSS, HTML, or a UI component, someone needs to verify it actually looks right in a browser. Traditional approaches have two extremes:
Manual checking
Open the browser, click around, eyeball everything. Slow, error-prone, and impossible to reproduce consistently.
Full E2E automation
Playwright/Selenium suites that are expensive to maintain, break on minor DOM changes, and take minutes to run.
The Lite Browser QA skill sits in the sweet spot: it gives AI agents (and humans) a fast, reliable way to verify UI changes using the lightest tool that fits the job.
Think of it like a medical triage system. A nurse doesn't order an MRI for every patient — a quick check, a thermometer reading, and a stethoscope handle 90% of cases. The MRI is reserved for when it's truly needed. This skill works the same way: quick screenshot for most checks, scripted interaction when needed, full browser automation only as a last resort.
The three-tier architecture
The skill picks the lightest tool that fits the task, organised into three tiers. Each tier adds capability but also adds complexity and execution time.
Static Screenshot
Headless Puppeteer captures a PNG of the page. Handles desktop, mobile, tablet, and element-specific shots. Takes 3–5 seconds.
GIF Recording
Captures sequential frames over a duration, stitches into an animated GIF. For animations, transitions, hover effects, and loading states.
Scripted Interaction
Inline Puppeteer scripts that click buttons, fill forms, navigate between states, and screenshot at each step.
Full Browser Automation
Claude-in-Chrome, Playwright MCP, or Antigravity Browser for live interaction in the user’s actual browser session.
Tier selection decision flow
When an agent needs to verify a UI change, it walks through this decision tree to pick the right tier:
BPMN process diagram (swimlane)
The same decision flow rendered as a formal BPMN 2.0 process diagram
with the QA Agent as a swimlane. This was generated using the
bpmn-creator skill with ISO/IEC 19510 compliant XML:

Click any diagram or image on this page to zoom in. Press Escape to close.
How each tier works
Tier 1: Static screenshot
The workhorse of the skill. A single Node.js script (screenshot.mjs)
launches an isolated headless Chrome instance via Puppeteer, navigates to the
target URL, waits for rendering, and captures a PNG.
@mermaid-js/mermaid-cli that is
already installed on the machine. Zero extra disk footprint.
| Flag | Default | Description |
|---|---|---|
| --url | required | Page URL to screenshot |
| --output | ./screenshot.png | Output PNG path |
| --full-page | false | Capture full scrollable page |
| --preset | — | mobile (375x812) / tablet (768x1024) / laptop (1280x720) / desktop (1400x900) |
| --selector | — | CSS selector for element-level screenshot |
| --wait | 2000 | Milliseconds to wait after load (for JS rendering) |
| --wait-for | — | CSS selector to wait for before capture |
| --multi-viewport | false | Take shots at all 4 preset sizes |
| --check-console | false | Report JS errors and warnings to stdout |
| --timeout | 30000 | Navigation timeout in ms |
Tier 1b: GIF recording
When the change involves animation, transitions, or time-based effects, a single PNG is not enough. Tier 1b captures sequential frames at a configurable FPS and stitches them into an animated GIF using ImageMagick.
| Flag | Default | Description |
|---|---|---|
| --record <ms> | — | Recording duration in milliseconds |
| --fps <n> | 5 | Frames per second (8-10 for smooth playback) |
| --record-action <js> | — | JavaScript to execute mid-recording (hover, click) |
| --action-at <ms> | 500 | When to fire the action (ms after start) |
Tier 2: Scripted interaction
For changes that require clicking buttons, filling forms, or navigating between UI states, agents write an inline Puppeteer script. This is still lightweight — no test framework, no config files, just a Node.js one-liner.
Analysis tools pipeline
Screenshots alone answer “what does it look like?” but not “what changed?” or “what elements are present?”. Three analysis tools extend the skill beyond simple capture:
BPMN collaboration diagram (swimlanes by role)
This formal BPMN 2.0 collaboration diagram shows how the three analysis tools operate as independent pools, each receiving a screenshot from the QA Agent orchestrator via message flows. The parallel gateway in the QA Agent pool fans out to all three tools simultaneously:

| Tool | What it does | Output | Speed |
|---|---|---|---|
| Visual Diff | Pixel-level comparison between two screenshots using ImageMagick compare |
Diff overlay image, similarity %, verdict (IDENTICAL / MINOR / SIGNIFICANT) | <1s |
| YOLO v11 | Detects UI elements (buttons, inputs, icons, checkboxes) with bounding boxes | Annotated image with 18+ detected elements and confidence scores | 264ms |
| OmniParser v2 | Full screen understanding — extracts a structured list of every UI element | 44+ icons/elements with positions and avg 68% confidence | 169ms |
Visual diff in detail
The visual-diff.sh script compares two screenshots pixel-by-pixel and
produces a diff overlay image with changed areas highlighted in red:
The verdict classification:
| Verdict | Threshold | Meaning |
|---|---|---|
| IDENTICAL | 0 pixels | No visual change detected |
| NEGLIGIBLE | <100 pixels | Sub-pixel rendering differences only |
| MINOR | <1% | Small localised change |
| NOTABLE | 1–5% | Review recommended |
| SIGNIFICANT | >5% | Visual regression likely |
Complete QA workflow
This sequence diagram shows the full end-to-end workflow when an agent uses the Lite Browser QA skill to verify a UI change:
Architecture mindmap
The full skill architecture at a glance, showing how all components relate:
Real-world test results
The skill was tested against the BACON Mesh Hub v0.2 (a D3.js force-directed network visualisation). Two UI states were captured and analysed with all tools:
Source screenshots
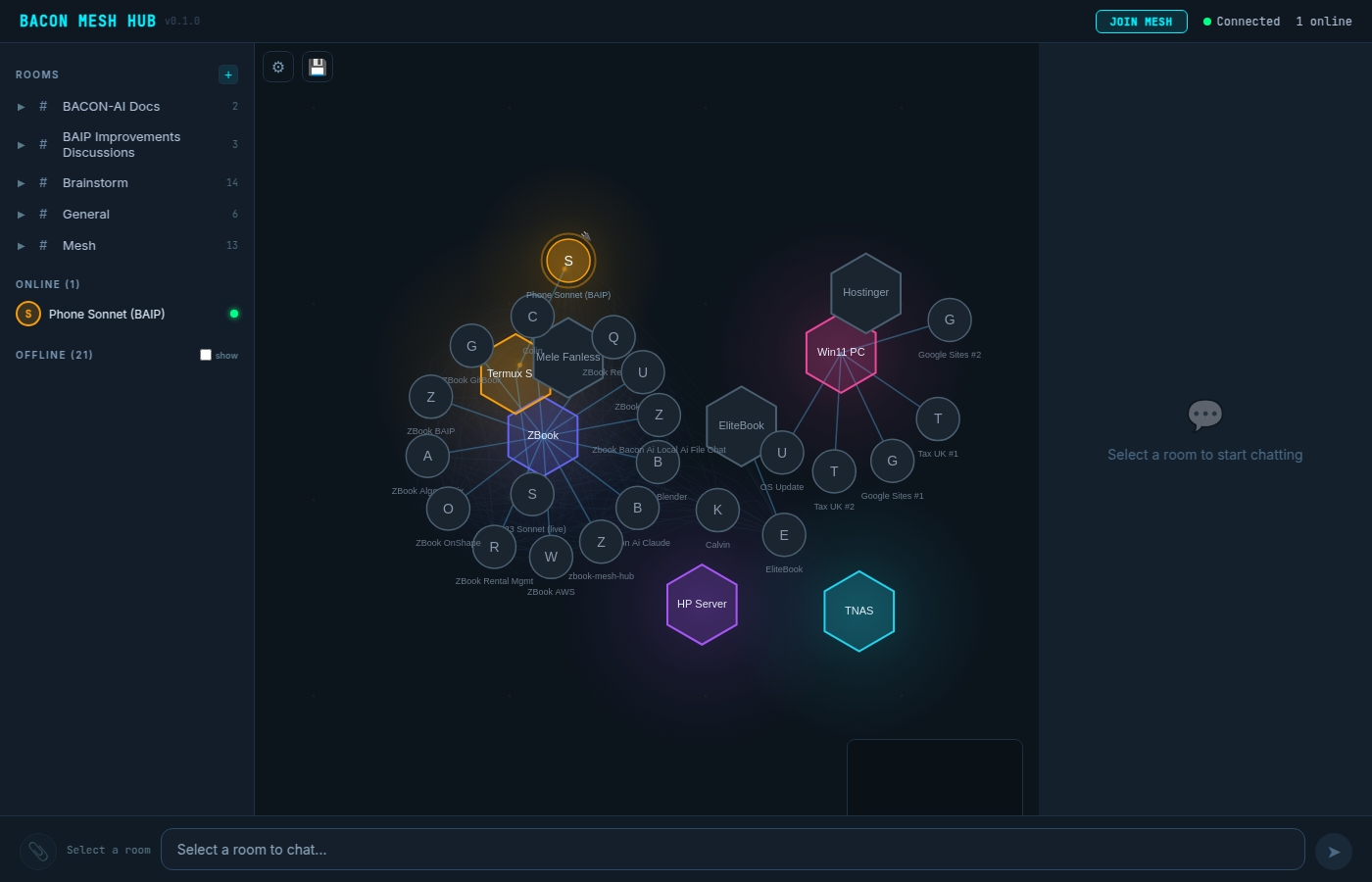

Analysis results




GIF recordings


Interactive comparison dashboard
The full interactive dashboard with tabbed views, slider comparison, and zooming was generated during the QA demo session. It includes all screenshots, analysis overlays, and side-by-side comparisons:
Integration with 7-step UX validation
The skill maps directly to the BACON-AI mandatory 7-Step UX Validation Checklist:
Tool coverage matrix
The table below maps every tool defined in the
bacon-ai-lite-browser-qa skill (SKILL.md v2.0.0) against what
this documentation page covers, and highlights any gaps.
| Tool / Capability | Use Case | Frequency | Docs Coverage | Gap Notes |
|---|---|---|---|---|
| Tier 1: Static Screenshot | Verify UI renders correctly after CSS/HTML/component changes. Desktop, mobile, tablet, element-specific, multi-viewport, and console error checking. | Every change | Full | — |
| Tier 1b: GIF Recording | Verify CSS animations, particle effects, loading states, hover transitions, and time-based visual behaviour. Supports mid-recording JavaScript actions. | Situational | Full | — |
| Tier 2: Scripted Interaction | Click buttons, open menus, fill forms, navigate between UI states via inline Puppeteer scripts. Multi-state screenshot sequences. | Situational | Full | — |
| Tier 3: Full Browser Automation | Live browser interaction via claude-in-chrome, Playwright MCP, or antigravity-browser. For auth flows, OAuth popups, cookie-dependent sessions, live demos. | Rare (~2%) | Covered | Mentioned in tier cards and decision flow; no dedicated section with examples (intentional — tool has own docs) |
| Tool A: Visual Diff | Pixel-level before/after regression detection using ImageMagick compare. 5 verdict levels from IDENTICAL to SIGNIFICANT. Configurable fuzz threshold. |
Every CSS change | Full | — |
| Tool B: YOLO v11 Detection | Fast bounding-box detection of UI elements (buttons, inputs, icons, checkboxes). Structural sanity check after refactors. Compare element counts before/after. | After refactors | Full | — |
| Tool C: OmniParser v2.0 | Full screen parsing — extracts structured list of all interactive elements with positions and confidence scores. For unfamiliar pages, accessibility audits, handoff documentation. | Rare / specialized | Full | — |
| Claude Vision (Read PNG) | Natural-language UI analysis — “does this look right?”, “is the spacing balanced?”. Qualitative assessment via Claude’s multimodal capability. | Subjective checks | Partial | Mentioned in sequence diagram and quick reference, but no dedicated section explaining usage patterns or example prompts |
| QA Workflows by Change Type | 4 prescriptive step-by-step workflows: CSS change, component refactor, new feature, full page audit. Each specifies which tools to run and in what order. | Reference guide | Full | — |
| Per-Tool Frequency Guidance | Daily / situational / rare usage classification with “When to use” and “When NOT to use” guidelines and tool limitations. | Reference guide | Partial | Frequency shown in this table. Skill has detailed “When to use / When NOT to use / Limitation” prose for each tool — not fully reflected |
| Tool Selection Quick Reference | Question-based lookup: “Did my CSS break?” → Pixel Diff, “Does the animation look right?” → GIF Recording, etc. | Reference guide | Full | — |
| Puppeteer Import Path & Notes | Technical detail: reuses mermaid-cli’s bundled Puppeteer to avoid 300MB separate Chromium install. Required --no-sandbox flag. |
Technical ref | Partial | Key design choice box mentions it. Full import path and rationale from skill not reproduced (intentional for human-facing docs) |
Coverage summary
The three “partial” items are intentional: Claude Vision usage is shown in context (sequence diagram + quick ref) rather than duplicating its own docs; per-tool frequency is shown in the table’s Frequency column; and the Puppeteer import path is a machine-specific technical detail omitted from human-facing documentation.
ML models evaluated
During development, six HuggingFace models were evaluated for UI analysis. Two were selected for integration:
| Model | Task | Size | Status |
|---|---|---|---|
| macpaw-research/yolov11l | UI element detection (bounding boxes) | 49 MB | Installed |
| microsoft/OmniParser-v2.0 | Full screen parsing + element extraction | 1.1 GB | Installed |
| microsoft/Florence-2-base | General visual QA | 930 MB | Evaluated |
| Qwen/Qwen2.5-VL-3B-Instruct | Vision-language model | ~7 GB | Evaluated |
| BAAI/BGE-VL-Screenshot | Screenshot similarity scoring | ~7 GB | Evaluated |
| microsoft/layoutlmv3-base | Document layout understanding | ~500 MB | Evaluated |
Which tool do I use?
Start with the question you need to answer, not the tool. This table maps the most common QA questions to the right tool:
| Question | Tool | Speed |
|---|---|---|
| Did my CSS change break anything? | Pixel Diff — screenshot before, change, screenshot after, diff | <1s |
| Does the page render correctly? | Screenshot (Tier 1) — quickest sanity check | ~3s |
| Does this animation look right? | GIF Recording (Tier 1b) — capture the motion | ~5s |
| Are all buttons/inputs still there? | YOLO — structural element count after refactors | ~300ms |
| What is every interactive element? | OmniParser — full inventory of unfamiliar pages | ~200ms |
| Does this “look good”? (subjective) | Claude Vision — Read the PNG, ask a qualitative question | N/A |
| Show the user a live demo | Full Browser (Tier 3) — only when live interaction is needed | Varies |
QA workflows by change type
Four prescriptive, step-by-step recipes. Pick the one that matches what you just changed:
1. CSS or styling change
The most common QA workflow. A simple before/after comparison catches both intentional changes and accidental side-effects.
2. Component refactor
Refactors risk removing or repositioning elements without realising. Compare element counts before and after:
3. New feature (adding a UI element)
When adding something new, the pixel diff should show change only in the area of the new element — red anywhere else means a side-effect:
4. Full page audit or handoff
When documenting a page for another agent, or doing a comprehensive QA pass before a release:
Quick reference commands
Never claim “UI tested” without at least a Tier 1 screenshot. The Lite Browser QA skill exists precisely to prevent the anti-pattern of declaring changes work without visual evidence. Take a screenshot, read it into the conversation, and verify before reporting success.